LLMCad阅读笔记
背景
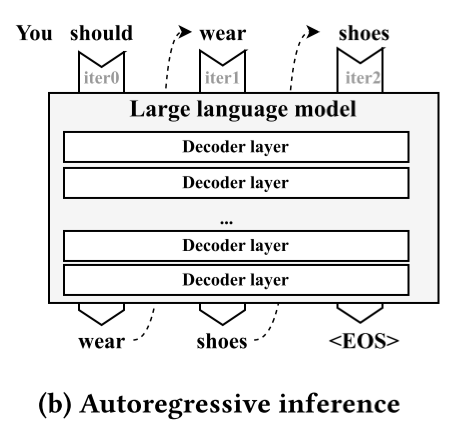
自回归推理:生成性语言模型采用自回归推理程序,该程序一次生成一个标记,并将该标记作为输入来生成下一个标记。例如,图2(b)演示了一个三次自回归迭代的推理过程。在第一次迭代中,模型将所有现有标记(“你应该”)作为输入,并生成输出“穿”。在下一次迭代中,新生成的“穿”将被输入到模型中,然后预测“鞋子”。这个过程持续进行,直到模型生成序列结束标记(<EOS>),表示生成过程的结束。自回归推理的性质为优化移动设备上的语言模型带来了独特的挑战。
自回归的特性使得传统的内存优化对生成型大型语言模型(LLM)几乎无效。值得注意的是,近年来,模型推理的内存优化一直是一个研究得很深入的话题[27, 32, 46, 78]。已经探索了各种系统级方法,如批处理[78]、计算/输入输出流水线[27]和智能swap[32, 46]。然而,这些工作几乎无法应用于移动设备上的LLM,原因是:(1)由于自回归推理需要顺序生成标记,所以并行化/批处理不可用;(2)由于输入/输出时间比计算时间长数百倍,重叠获得的好处有限。此外,像量化[25, 31, 66, 76]这样的算法方法虽然能够带来几倍的内存减少(例如,FP16→INT4[25]),但其效率有限,因为低位精度(例如,2位)已被证明不足以保持模型的能力[25, 36, 76]。
方法
首先,LLMCad将输入文本输入到内存驻留模型中,并生成一个token tree。token tree是由内存驻留模型生成的中间结果。与token sequence不同,sequence中的每个令牌只有一个后续令牌,而令token tree中的一个令牌可以有多个候选后续令牌。每个候选令牌代表一个候选令牌序列(称为分支)。这基于这样一个观察:有时内存驻留LLM生成的“次优”令牌实际上是目标LLM的真实输出,例如,备选令牌“cap”。在实践中,任何置信度高于阈值(例如,30%)的候选令牌都会生成一个分支。内存驻留LLM生成的每个令牌都引入了一些“不确定性”(置信度分数)。一旦这种不确定性在输出句子中积累到一定程度,就调用目标LLM来验证自上次验证以来生成的所有分支所示。值得注意的是,可以在一次目标LLM推理中完成对N个令牌的验证,因此比使用它N次生成一个令牌要快得多。
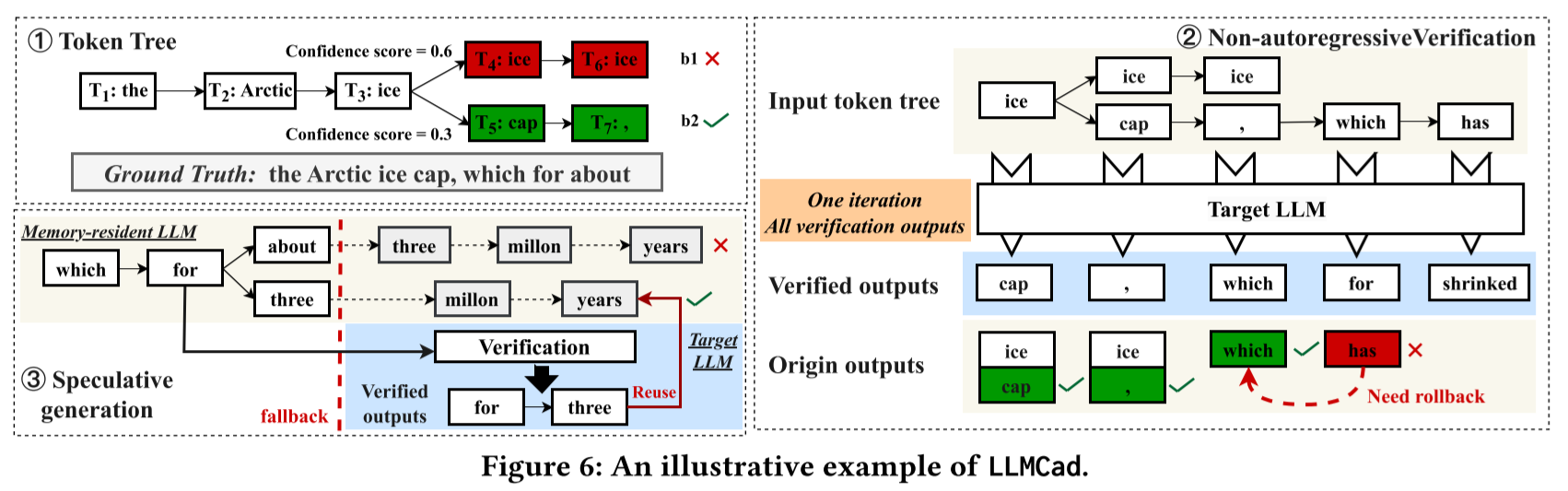
两个问题:
- 分支竞争计算资源(例如,GPU)来通过运行内存驻留模型生成后续令牌。在一个时间点上,哪个分支应该获得资源来延长其令牌序列?向错误的分支生成令牌(后续再用目标模型验证)会浪费计算资源并延迟真正令牌的生成。
- 从不同分支生成令牌需要在分支上下文之间切换。如何高效地从不同分支生成令牌?这个设计至关重要,因为LLMCad需要频繁地在多达数十个分支之间切换。
方法:
- 基于置信度的分支调度器
- 树解码器:通过一个mask向量来避免context switching
- Speculative generation pipeline
实验
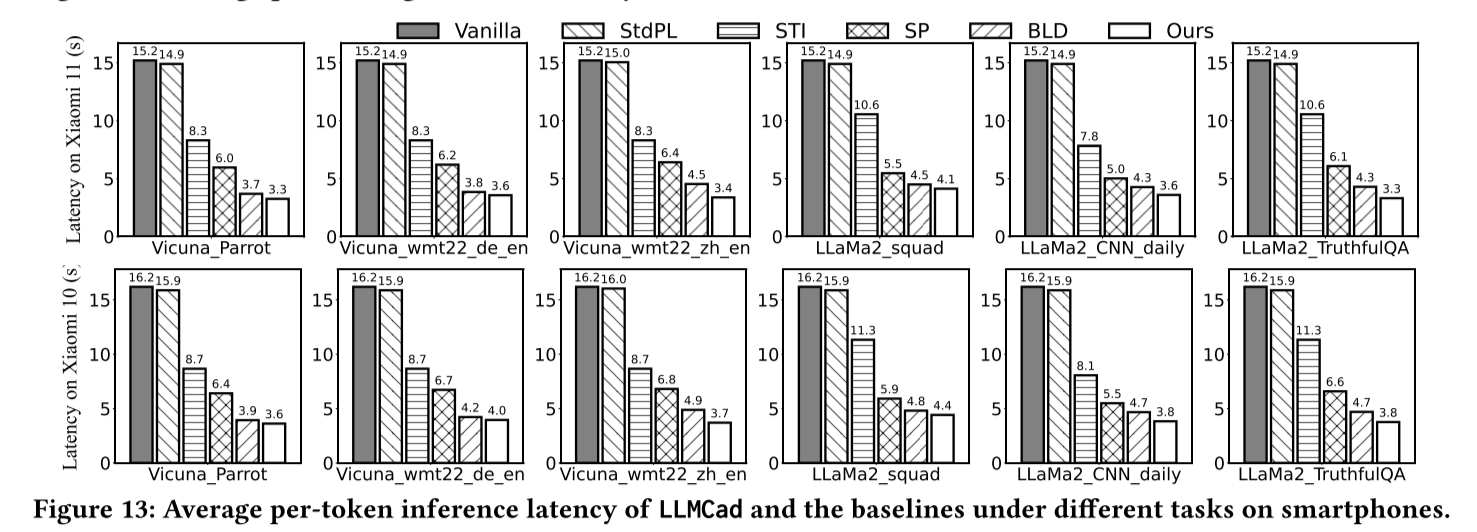
可能探索的方向:
- 异构计算
- 手机CPU有大小核之分,目前的llama.cpp使用任务均分的方式;是否可以实现更合理的任务分配?
- CPU+GPU+DSP?
- Long context
- 如何保证缩减draft model的context window之后仍然可以保持较高的准确度?
- Sparse attention
- 如何保证缩减draft model的context window之后仍然可以保持较高的准确度?
- draft model的选择
- 大小?
- 量化方式?
- 对齐?
- 采样方式
- 对target model进行贪心采样会增加draft的拒绝概率
- Temperature
- Top-p
- Top-k
- Beam search
- gumble softmax
- 对target model进行贪心采样会增加draft的拒绝概率