TensorIR阅读笔记
ASPLOS 2023
概览:
- 提出了一种新颖的张量化程序抽象,将张量化计算与循环转换分离。同时,相同的抽象允许我们统一表示硬件或库支持的张量基本指令(tensor intrinsics)。
- 构建转换原语,生成张量化程序优化的巨大搜索空间,并加入正确性验证。
- 设计并实现了一种新的张量化感知自动调度程序。
TensorIR:
图4给出了一个TensorIR程序的示例。我们引入了TensorIR的Python-AST(抽象语法树)方言,让开发人员可以直接在Python中构造和转换程序。一个TensorIR程序包含三个主要元素:多维缓冲区、循环嵌套(在GPU设置中可能有线程绑定)和块。一个块可以包含一个或多个带有子块或与计算内容相对应的命令语句序列的嵌套循环。这种表示允许我们将计算划分到相应的子块(块)区域,并使用存储在块签名中的依赖信息进行有效的程序转换。

变换原语:
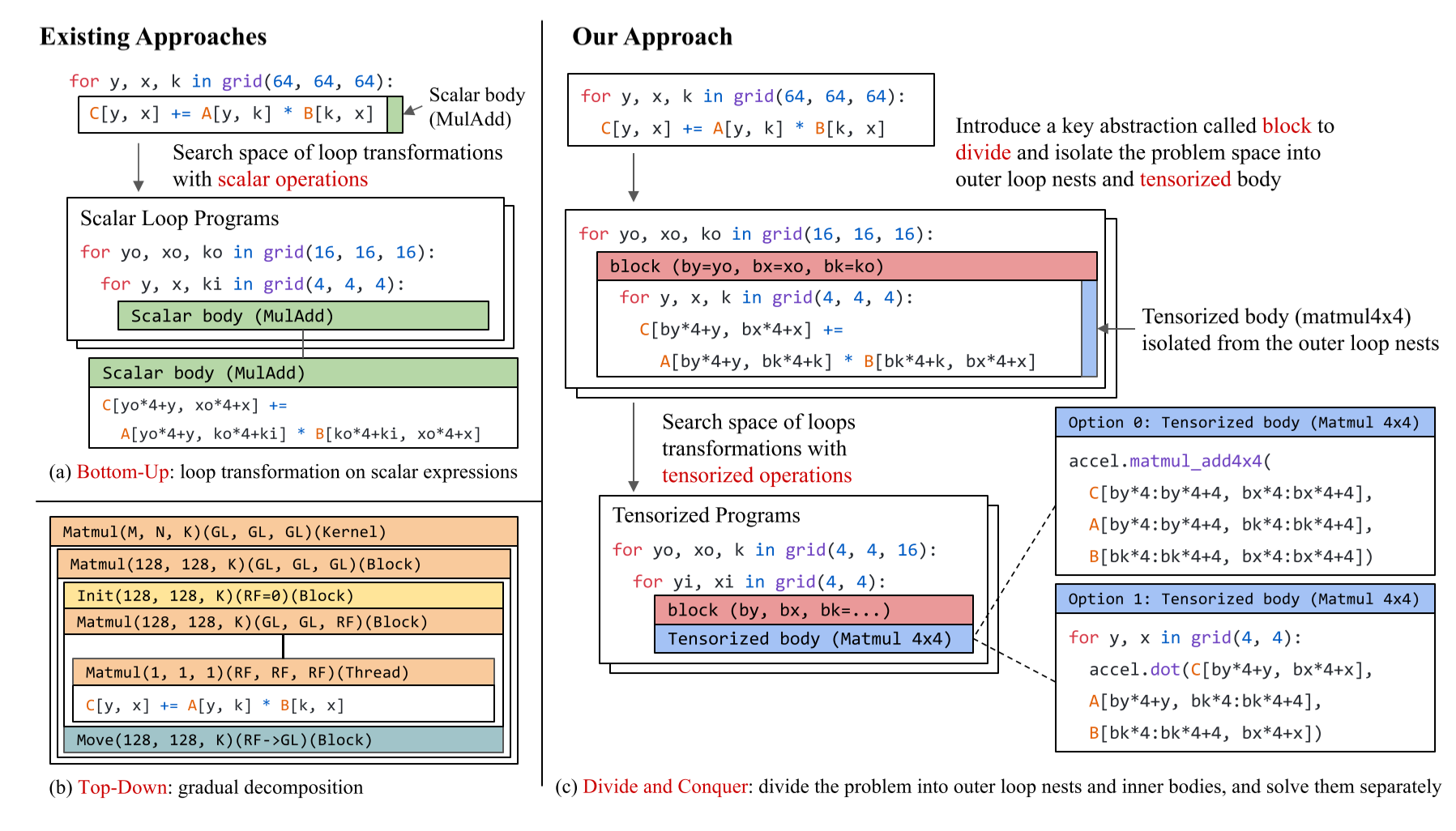
如果一个块只包含以子块为叶子的循环嵌套,则该块是可调度的。我们可以通过分析子块签名及其依赖信息,在可调度块内转换循环嵌套和子块计算位置。值得注意的是,可调度块可以包含不可调度的子块(例如,不透明的tensor core计算)。一个不透明的块也可以包含一个可调度的子块。基于块隔离,我们仍然可以独立地有效地探索可调度部分的搜索空间,同时保持不透明块不变。
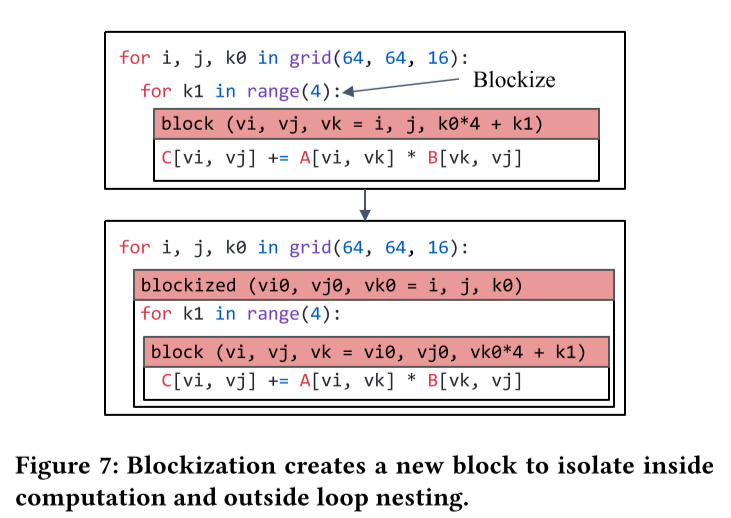
变换原语包括循环变换和blockization两个部分。循环转换原语保留了块的整体层次结构,然而有时将子区域的计算隔离到新的子块中是有帮助的。我们称这种转换为块化。如图7所示,一个块化程序不再基于标量进行计算,因为新的子块对应于张量化计算。除了块化,我们还引入了可以改变块层次结构的原语。例如,我们提供了缓存原语,用于将子块引入共享内存中以缓存输入数据。我们还提供了合并块的原语。
张量化程序:
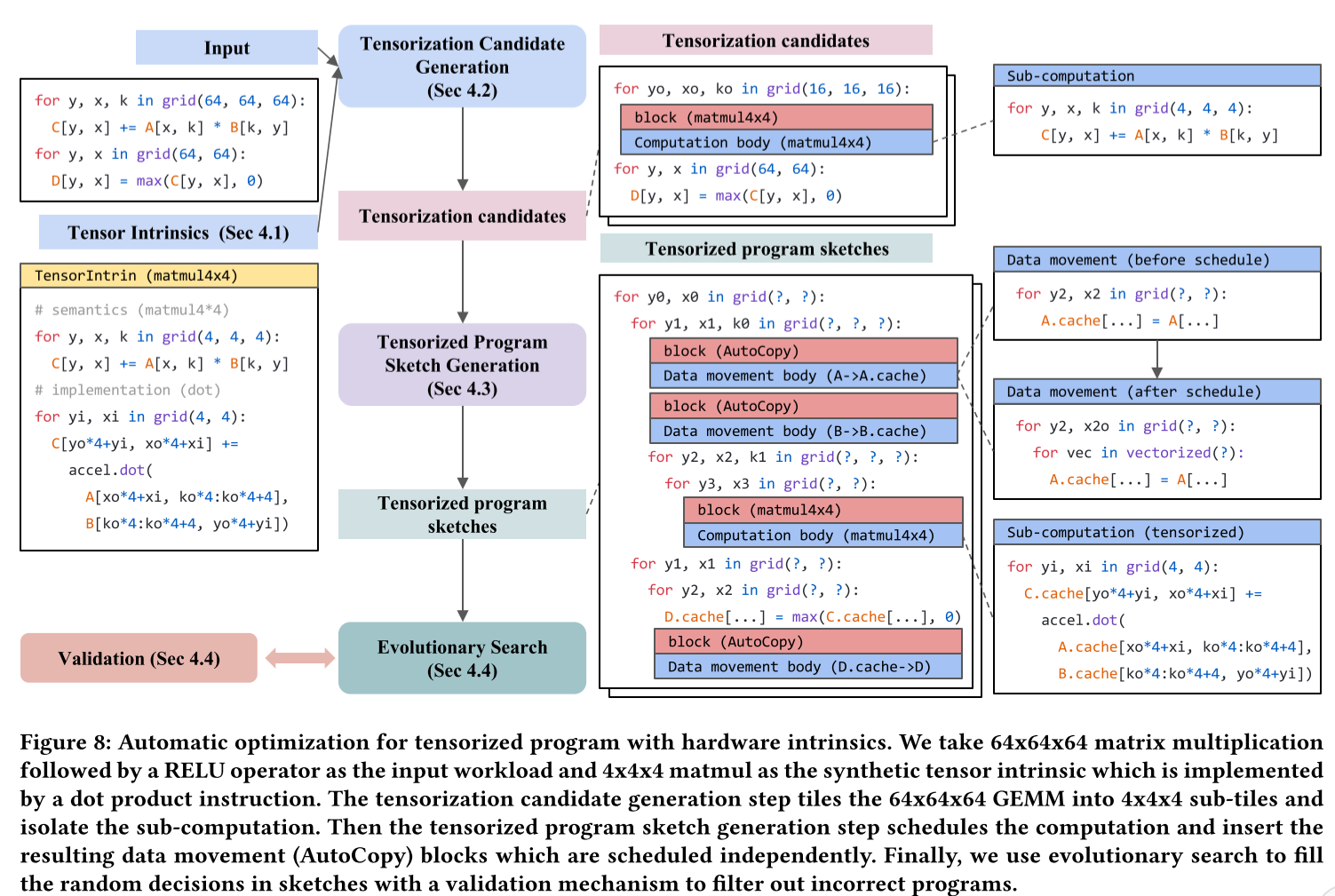
自动调度器接收用户的工作负载描述,和有关硬件平台的张量基本指令描述作为输入,首先通过检查计算模式来生成张量化的候选项,然后,它生成使用张量化程序草图候选项,然后根据计算模式决定数据移动。对于由张量化程序草图带来的给定搜索空间,执行基于机器学习的成本模型指导的evolutionary search,获得最优的方案。
如何生成张量化程序草图?假如我们的张量基本指令是这样的:
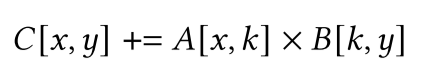
那么我们很容易就能匹配如下工作负载

但假如我们的工作负载是这样的,就很难与张量基本指令匹配
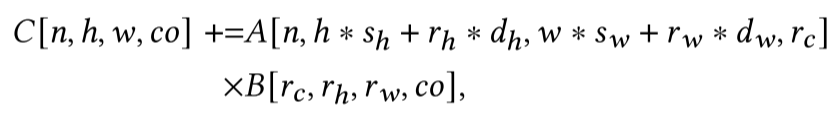
解决的办法是对$A$进行重写
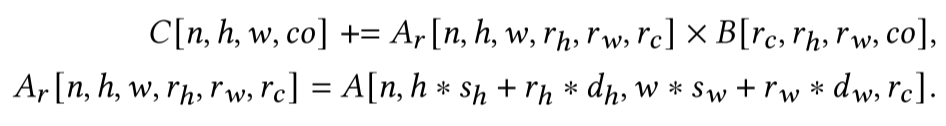
观察可以得到,假如把$[r_h,r_w,h_c]$压缩成一个维度$k$,$[n, h, w]$压缩为维度$x$,用$y$表示$co$,就有了: \(C[x, y] += A_r[x, k] * B[k, y]\) 这时计算负载就能与张量基本指令匹配。
我们称这种转换为ReIndex。为了将新计算与张量内在函数匹配,我们检查每个迭代器出现的缓冲区访问。例如,我们注意到$n, h, w$和$x$出现在$A(Ar)$的索引中,$c, o$和$y$出现在$B$、$C$的索引中,$rh, rw, rc$和$k$出现在$A$、$C$的索引中。然后,我们可以通过检查它们的出现模式来将计算中的迭代器与张量基本指令中的迭代器匹配。具体来说,我们将$ \text{fuse}(n, h, y)$映射到$x$,$co$映射到$y$,$\text{fuse}(rh, rw, rc)$映射到$k $。这里的$\text{fuse}()$是将多个迭代器融合在一起,(即将多个维度压缩成一个维度)
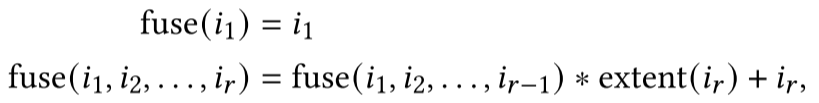
之后我们就能将计算转换为:
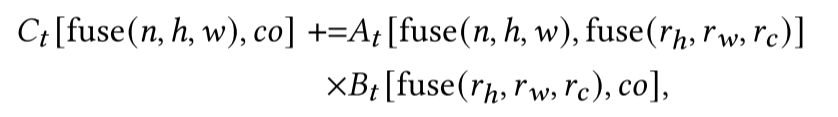
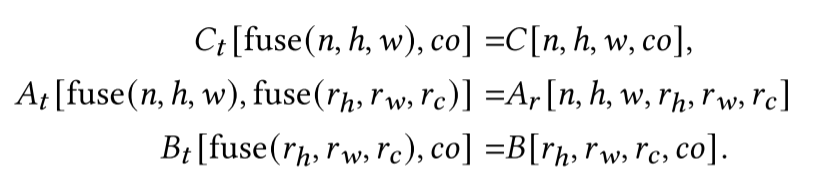
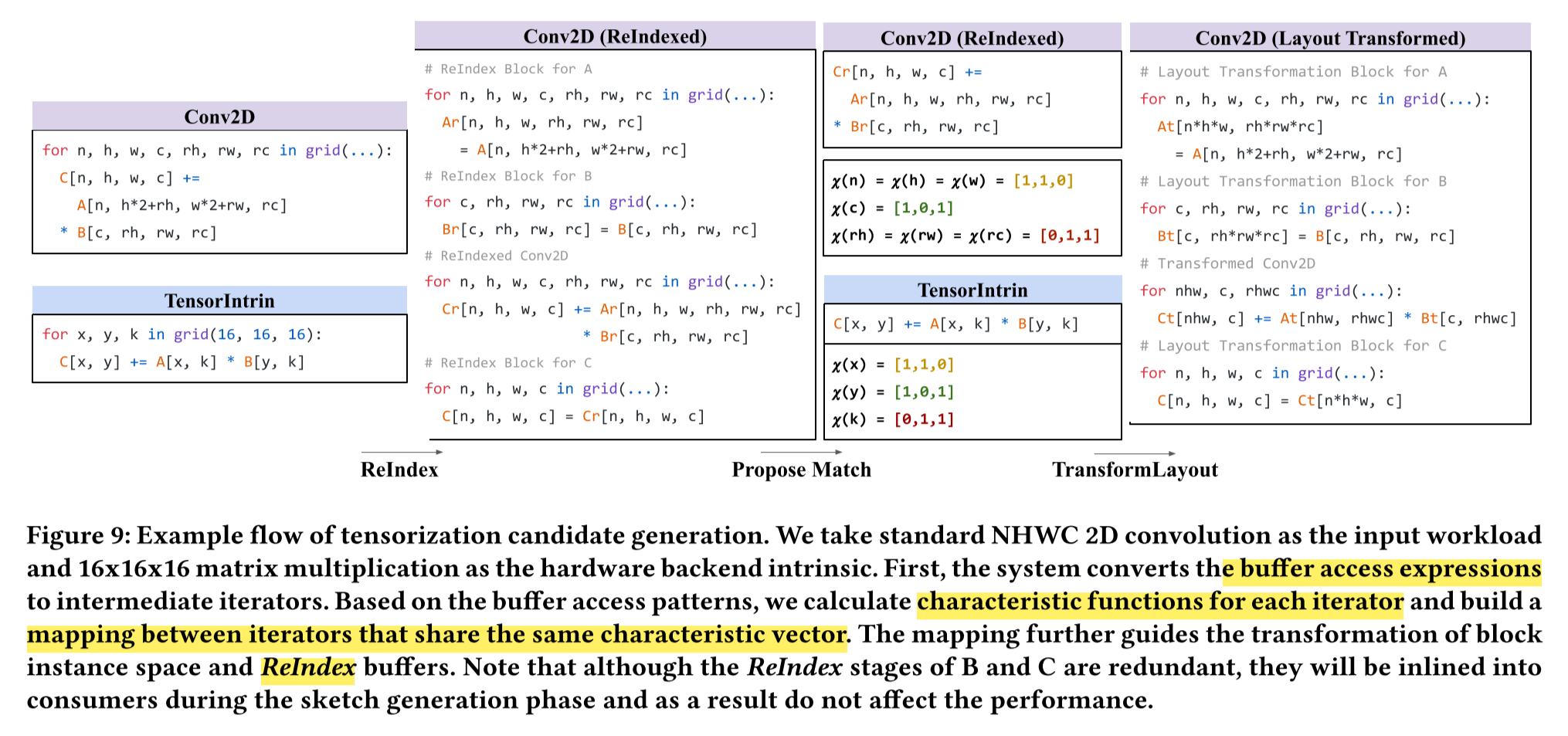
我们插入布局重写块分别将$A, B, C $重写为$A_t, B_t, C_t$,并使用$A_t, B_t, C_t$重写计算体。经过这些步骤后,计算体与张量基本指令兼容。
重新组织的块实例,其计算空间的形状可能不能被张量内在函数的子问题大小整除。因此在计算块和输入/输出操作数上进行必要的填充,以达到最接近的可整除形状。然后,我们执行切片以创建内部循环,以匹配张量内在函数的循环嵌套,并进一步将内部循环块化以隔离相应的张量计算。
程序草图生成:由于张量基本指令大大提高了计算的吞吐量,数据移动成为张量程序的瓶颈。此外,数据移动决策通常取决于计算调度决策,如切片、线程绑定、执行范围和生产者-消费者数据流粒度。借鉴这些,我们将数据移动作为我们的自动调度器中的一等公民,并将它们与计算调度分离。具体来说,我们将AutoCopy块插入到程序草图中,决定执行数据移动的位置(图8)。复制块隐藏了内存调度细节,仅在块签名级别公开必要的缓冲区访问信息。隔离的复制块允许草图生成独立做出计算调度决策,而无需考虑如何进行数据移动。AutoCopy块的主体描述了数据移动任务的细节,包括缓冲区位置映射、线程和存储范围要求。数据移动调度器将此信息作为输入,并执行与内存相关的调度转换,例如插入中间缓存阶段、利用数据移动张量内在函数、向量化、协同获取或跨步填充以避免bank冲突。
最后执行类似于AutoSchedule的evolutionary search进行性能调优。
问题:找不到执行入口;只能匹配简单的张量基本指令;data layout transformation作为block放在算子里面可能导致冗余的转换,可以结合整个计算图全局优化
2023年6月14日
硬件专门化的浪潮增加了机器学习编译问题的复杂性。现代硬件后端为了加速张量计算引入了专门的原语(例如,Nvidia Tensor Core,Google TPU)。领域专家还开始开发微内核原语,组织一系列高度优化的指令来执行子计算,以加速特定领域的张量运算库。这些硬件指令和微内核原语通常在多维张量上操作,并有效地执行诸如多维加载、点积和矩阵乘法等张量操作。我们将这些不透明的张量计算加速构造称为张量内部函数(tensor intrinsics),并将使用这些内部函数的转换过程称为张量化。为了充分发挥这些硬件后端的优势,现代机器学习系统需要优化包含多层循环嵌套、多维加载和张量内部函数的程序,我们称之为张量化程序优化问题。

这篇文章提出了一种使用自动编译方法来解决张量化程序优化问题。在过去的机器学习编译工作中,大多数都只对循环嵌套进行变换,而不自动处理张量化程序。这篇文章的目标是解决以下关键挑战:
- 张量化程序的抽象。为了构建一个自动化的张量化程序编译器,我们需要一个抽象,能够实际捕捉给定机器学习算子的等价张量化计算。这种抽象需要表示多维内存访问、线程层次结构和来自不同硬件后端的张量化计算原语。该抽象还需要具有足够的表达能力,以表示机器学习中感兴趣的大多数算子。
- 张量化程序优化。另一个挑战是自动为给定算子生成优化的张量化程序。编译器需要利用领域专家可能使用的丰富技术集,包括有效利用循环平铺、线程和数据布局变换。重要的是,现在需要结合张量化计算进行这些变换。我们需要一种有效的方法来找到给定搜索空间的最优的张量化程序。
方法:
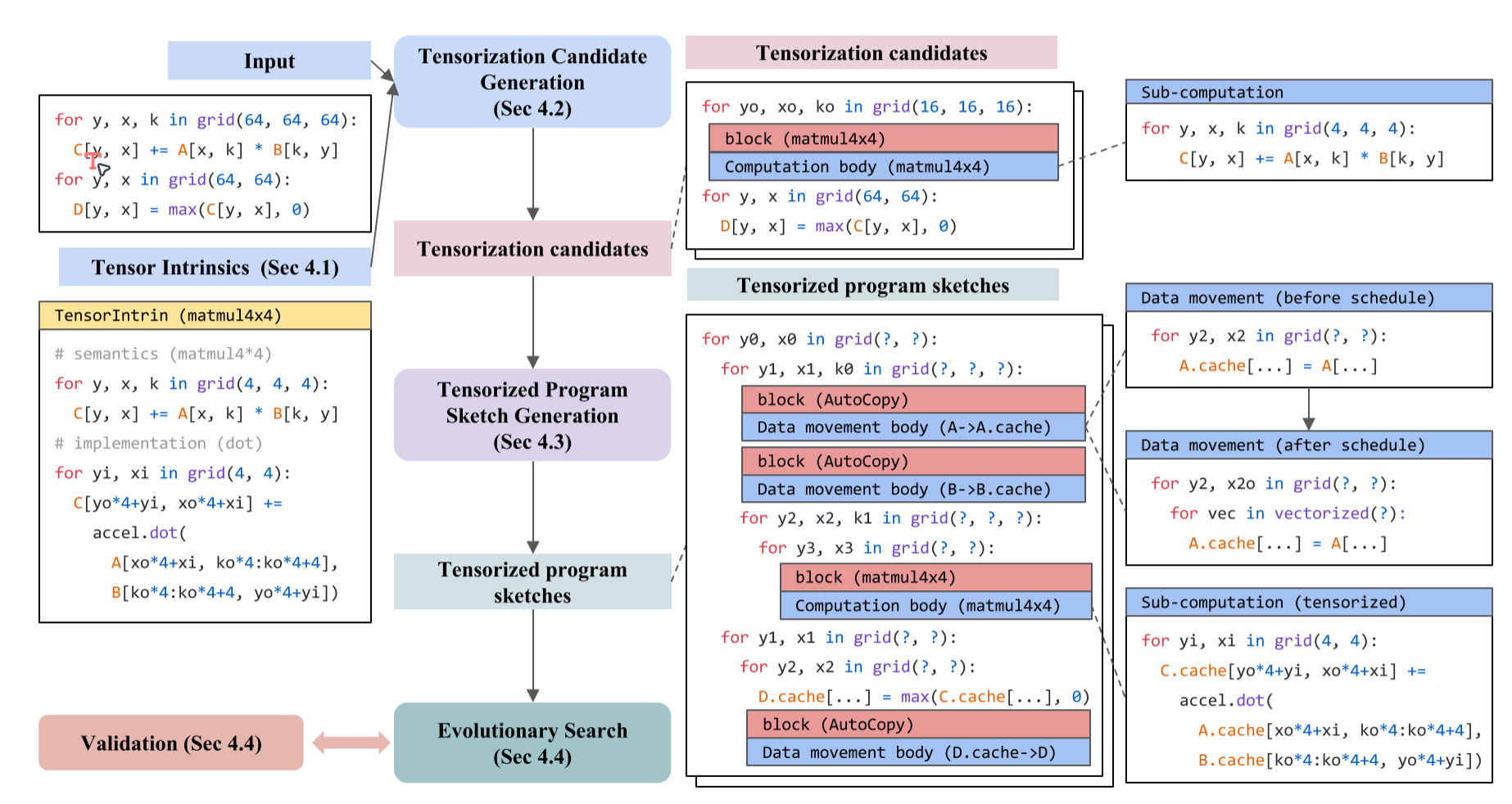
第一步:张量化候选生成

第二步:张量程序草图生成
讲得很简略,最重要的理念在于将数据移动作为一等公民,放在单独的block里面进行调度。
现有的张量程序的自动调度器将其设计集中在计算的调度上,并以次要优先级处理不同内存范围之间的数据移动。然而,由于张量本质极大地提高了计算的吞吐量,数据移动成为张量程序的瓶颈。因此本文将数据移动作为自动调度器中的一等公民,并将其与计算调度解耦。具体来说,我们在决定执行数据移动的地方插入AutoCopy块,从而隐藏复制块内存调度细节。隔离的复制块使得调度程序可以独立地针对计算做出调度决定,而不考虑如何进行数据移动。AutoCopy块的主体描述了数据移动任务的详细信息位置映射、线程分配和存储范围要求。数据移动调度器将此信息作为输入,并执行与内存相关的调度转换,例如插入中间缓存、利用内置函数加速、向量化、cooperative fetch(用在CUDA上)等等。
第三步:进化搜索。讲得也很简略,基本继承自TVM。
思考
主要讲TensorIR的设计,次要讲张量化的实现。
文章提到,数据移动往往成为程序的瓶颈。是否可以考虑不同算子之间的数据布局的一致性,避免一部分的数据移动?