Transformer笔记
模型结构
Transformer模型大致分为encoder only、decoder only、encoder-decoder这三类,其中encoder only模型主要用于处理图像和音频;decoder用于生成文字。我们主要讨论decoder模型。
decoder only模型结构如下图所示,由input、output和若干个串联的decoder block组成,
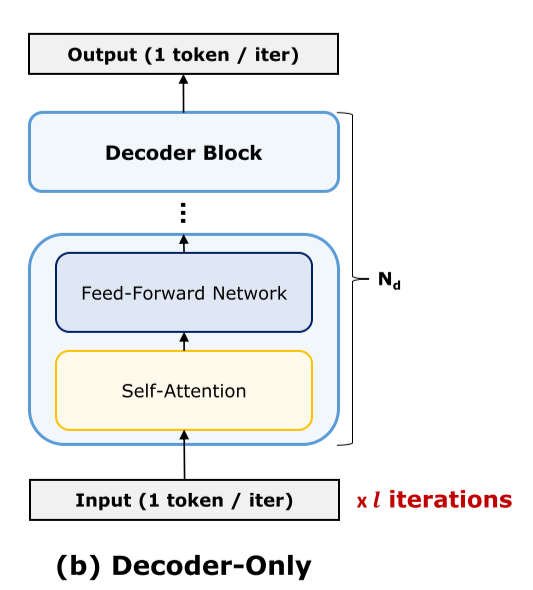
Transformer一个很重要的特点是其中间张量具有dynamic shape,因此在不同的工作状态下,张量的形状会有所不同。因此我们需要分别讨论不同的工作状态。
decoder only模型有两种工作状态:
- Prefill phase:称为预处理或encoding;读取一段prompt,计算并缓存每一层的key和value,这个缓存称为KV Cache
-
Decode phase:生成新的token的阶段,每次生成一个token;具体来说,将上次生成的token用作这次推理的输入,得到新的一个token;新的token作为输入再进行推理,得到下一个token;直到获得< end_of_text >
首先讨论更为典型的decode phase
- input只包含一个矩阵乘法算子,输入用1-hot编码表示上一个生成的token,形状是$\text{n_vocab} \times 1$,;输出形状是$d \times 1$
- 每个decoder block的输入和输出都是形状为$d \times 1$
- output是input的逆过程,输入是$d \times 1$,输出是$\text{n_vocab} \times 1$,表示下一个token的概率分布;采样程序从概率高的vocab中选择一个作为模型输出
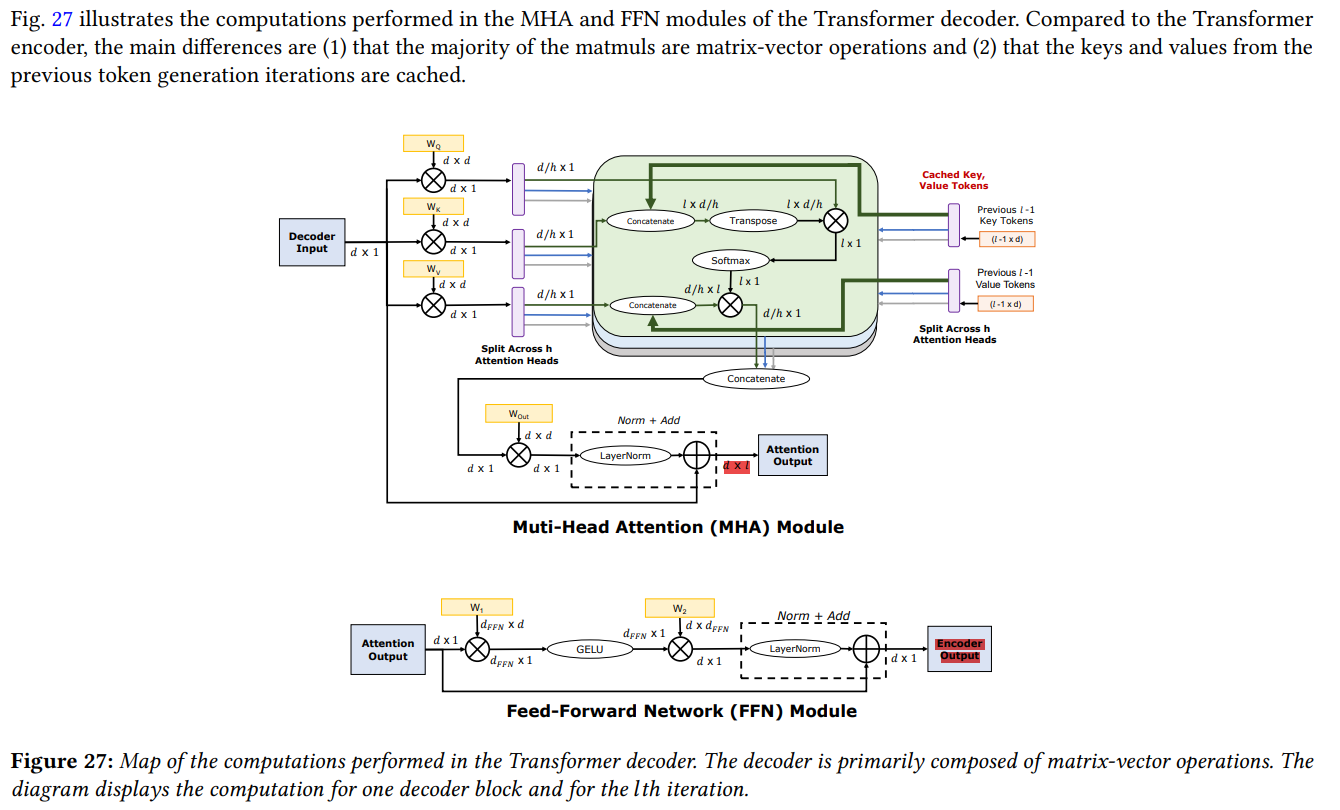
decoder block
- 每个decoder block的输入是一个$[d \times 1]$的张量
- 首先进入Multi-Head Attention模块,这个张量与$W_q$、$W_k$、$W_v$相乘,得到3个$d \times 1$的张量;接着这三个向量都进行垂直的切分,变为$h$个$\frac d h \times 1$的张量($h$称为注意力头数量),其中第$i$个分别为$q_i$、$k_i$、$v_i$($d \times 1 \to h \times \frac d h \times 1$)
-
假设之前序列长度为$l-1$,则kv cache中,第$i$个注意力头对应的k cache和v cache形状均为$\frac d h \times (l-1)$;$k_i$与kv cache进行拼接并存回cache($[\frac d h \times (l-1) \frac d h \times 1] \to [\frac d h \times l]$),得到$\frac d h \times l$的张量,称为$K_i$和$V_i$ - $\text{softmax}(q_iK_i)$得到形状为$l \times 1$的张量,称为attention score(softmax是reduce op,可能的优化:分块、pipeline)
- $\text{attn_score}_i \times V_i$得到$output_i$,形状为$\frac d h \times 1$;连接得到$output$($d \times 1$)
- 乘上$W_\text{out}$、归一化、残差连接
FFN
- 向高维度投影后再投影回低纬度:$[d \times 1] \to [n_ff \times 1] \to [d \times 1]$
- 残差连接
分析
- FLOPs: 浮点乘和浮点加操作的数量
- MOPs: 内存操作数量
-
Arithmetic intensity

decode phaseFLOPs和MOPs分析
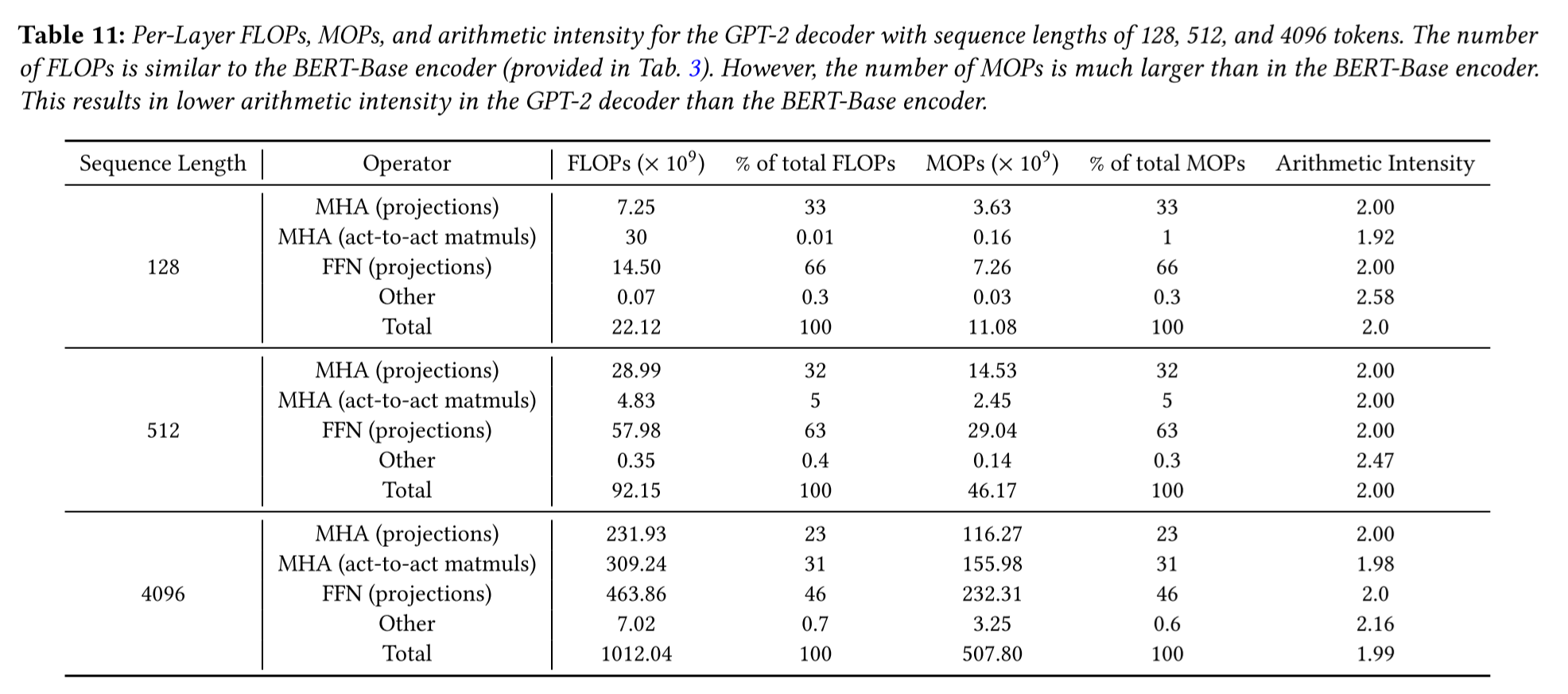
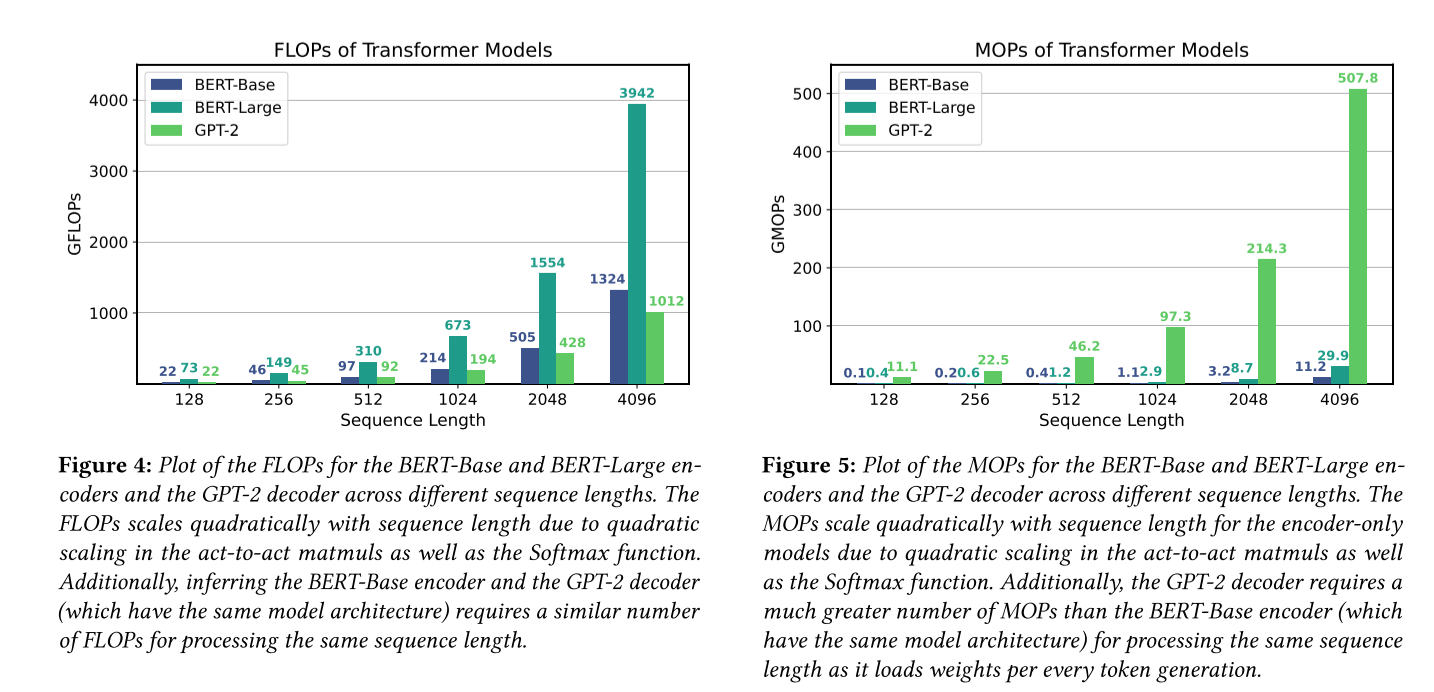
注意到在decode phase,模型的arithmetic intensity都在2左右;对比常见GPU的浮点性能和访存性能,以RTX4060为例:
- 浮点性能:15.39TFLOPs
- 访存带宽:使用GDDR6显存,带宽在768GBps左右
浮点性能比访存带宽高出20-30倍,因此使用GPU进行decode phase推理的性能瓶颈在于IO
接下来讨论prefill phase,假设当前要解码的序列长度为$n$,计算流程和上面的decode phase没有差异,唯一的区别在于所有值为1的张量维度变成$n$
| operator | in 0 | in 1 | out | FLOPs | MOPs | count | Arithmetic Intensity |
|---|---|---|---|---|---|---|---|
| MHA (casting) | $n \times d$ | $d \times d$ | $n \times d$ | $2nd^2$ | $(2n + d)d$ | 4 | $\frac {2d} {2 + \frac d n}$ |
| MHA (act-to-act) | $n \times d/h$ | $d/h \times l$ | $n \times l$ | $2ndl/h$ | $(n+l) \times d/h + n \times l$ | 2 | $\frac {2dl} {\frac 1 n dl + d + lh}$ |
| FFN | $n \times d$ | $d \times n_ff$ | $n \times n_ff$ | $2nd\ \text{n_ff}$ | $d (n+n_ff) + n \times n_ff$ | 2 | $\frac {2d \times \text{n_ff}} {\frac 1 n d \times n_ff + d + n_ff}$ |
其结果是: \(\text{arithmetic\_intensity} \approx 2n\) 计算结果如下,三个表分别对应三种算子(MHA (casting)、MHA (act-to-act)、FFN)的算术强度:
MHA (casting) :
| l\n | 1 | 2 | 4 | 8 | 128 | 512 | 4096 |
|---|---|---|---|---|---|---|---|
| 128 | 1.999024 | 3.996098 | 7.984405 | 15.93774 | 240.9412 | - | - |
| 512 | 1.999024 | 3.996098 | 7.984405 | 15.93774 | 240.9412 | 819.2 | - |
| 4096 | 1.999024 | 3.996098 | 7.984405 | 15.93774 | 240.9412 | 819.2 | 2730.667 |
| 32000 | 1.999024 | 3.996098 | 7.984405 | 15.93774 | 240.9412 | 819.2 | 2730.667 |
MHA (act-to-act):
| l\n | 1 | 2 | 4 | 8 | 128 | 512 | 4096 |
|---|---|---|---|---|---|---|---|
| 128 | 1.969231 | 3.878788 | 7.529412 | 14.22222 | 85.33333 | - | - |
| 512 | 1.980658 | 3.923372 | 7.699248 | 14.84058 | 113.7778 | 170.6667 | - |
| 4096 | 1.984016 | 3.936569 | 7.750237 | 15.03119 | 126.0308 | 199.8049 | 240.9412 |
| 32000 | 1.984435 | 3.938219 | 7.756636 | 15.05528 | 127.7445 | 204.1467 | 247.2833 |
FFN:
| l\n | 1 | 2 | 4 | 8 | 128 | 512 | 4096 |
|---|---|---|---|---|---|---|---|
| 128 | 1.999330 | 3.997322 | 7.989295 | 15.95724 | 245.4746 | - | - |
| 512 | 1.999330 | 3.997322 | 7.989295 | 15.95724 | 245.4746 | 874.0844 | - |
| 4096 | 1.999330 | 3.997322 | 7.989295 | 15.95724 | 245.4746 | 874.0844 | 3453.490 |
| 32000 | 1.999330 | 3.997322 | 7.989295 | 15.95724 | 245.4746 | 874.0844 | 3453.490 |
- 但当n比较大时,MHA (act-to-act)的arithmecit intensity趋近于上限256,相较于其他操作低很多,可以作为异构计算中子图划分的依据
因此encode阶段处理每个token的平均时间比decode阶段短得多

主要困难
- Latency
- IO
- Flash attention(主要用于训练):
- V1:https://proceedings.neurips.cc/paper_files/paper/2022/file/67d57c32e20fd0a7a302cb81d36e40d5-Paper-Conference.pdf
- V2:https://arxiv.org/pdf/2307.08691.pdf
-
Speculative decoding:Accelerating large language model decoding with speculative sampling
- 为什么模型天然可以执行validation?因为输入$n$个token时,模型的输出是$\text{n_vocab} \times n$,其中第$i$列第$j$行的元素表示第$i$个token的下一个输出是$j$的概率
- 因此只需要用某个token和上一个输出对比即可,假如相应的概率很小,说明两次推理结果发生冲突,采用validation的结果,并从抛弃这个token之后的结果,重新推理
- 可以在异构设备上进行,比方说CPU进行inference,GPU进行validation,充分利用GPU浮点性能强的优点
-
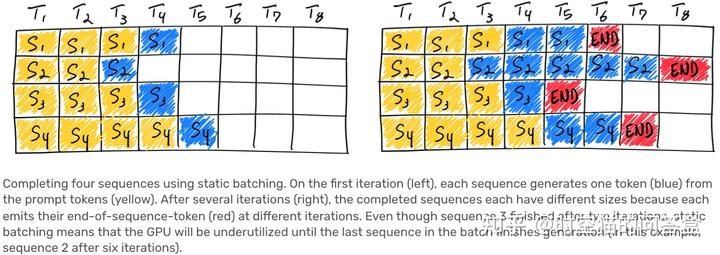
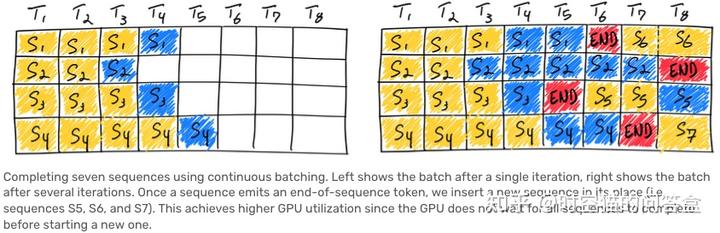
Continuous batching:Orca: A Distributed Serving System for Transformer-Based Generative Models
- Batching:同时生成多个序列
- Continuous batching:不能假设所有序列的长度相同,因此当一些序列结束生成之后,插入新的序列来提高利用率
- Flash attention(主要用于训练):
- Parallization
- Flash decoding:https://crfm.stanford.edu/2023/10/12/flashdecoding.html
- IO
- Memory
- Quantization
- 4-bit GPTQ:https://arxiv.org/abs/2210.17323
- Sparsification
- Paging:Efficient memory management for large language model serving with pagedattention
- Quantization
- Long context
- Sparse attention:https://arxiv.org/abs/1904.10509
以下是私货部分
Long Context
为什么关注long context
- 随着sequence length的增长,MHA (act-to-act)的FLOPs和MOPs会成正比增长
- kv cache也会成正比增长:在llama-2-7b上,一个token对应512K参数(2MB内存);32k token对应16B参数(64GB内存),GPU memory装不下
- 优化latency需要非常熟悉GPU或者加速硬件的底层细节
- 优化memory离不开量化和剪枝,需要非常了解模型的特性
llama-2-7b
| Sequence Length | Operator | FLOPs per token (× 10^6) | MOPs per token (× 10^6) |
|---|---|---|---|
| 128 | MHA (projections) | 4096 | 2048 |
| MHA (act-to-act matmuls) | 64 | 32 | |
| FFN (projections) | 5504 | 2752 | |
| Other | - | - | |
| Total | 9664 | 4832 | |
| 512 | MHA (projections) | 4096 | 2048 |
| MHA (act-to-act matmuls) | 256 | 128 | |
| FFN (projections) | 5504 | 2752 | |
| Other | - | - | |
| Total | 9856 | 4928 | |
| 4096 | MHA (projections) | 4096 | 2048 |
| MHA (act-to-act matmuls) | 2048 | 1024 | |
| FFN (projections) | 5504 | 2752 | |
| Other | - | - | |
| Total | 11648 | 5824 | |
| 32768 | MHA (projections) | 4096 | 2048 |
| MHA (act-to-act matmuls) | 8192 | 8192 | |
| FFN (projections) | 5504 | 2752 | |
| Other | - | - | |
| Total | 25984 | 12992 |
想法:如何尽可能高效地利用硬件?在本地部署transformer的一个问题是,当一轮对话结束后,需要等待用户的下一次输入,这期间的空闲时间能否利用起来?
Lora: Low-rank adaptation of large language models:finetune的$\Delta W$是low rank(低秩)的
Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers:finetune和ICL本质上统一
猜想:context的某种形式也是低秩的
- 实验1:kv cache
- 结果:k和v都不是low rank的
- 实验2:QK(attention score)
-
结果:QK是低秩的
-
初步想法:令$X=QK$,$X’=AB$,则$K’=Q^+AB=(Q^+A)(B)$实现近似;同理可以对$V$近似:$O=VX \approx VAB$,所以$V’=(AB)^+O=(B^+A^+)O=(B^+)(A^+O)$实现近似
-
问题:
- $X$和$K$都是变长的,每次推理后都进行分解的计算开销很大
- work around:执行完一轮对话之后进行一次压缩
- 与sparsification相比优势不显著
- 不会完全丢弃信息,只会引入误差(是否更好?)
- 位置编码:ALiBi等相对位置编码需要知道token之间的距离,假如使用稀疏注意力需要额外保存这一信息,导致开销
- $X$和$K$都是变长的,每次推理后都进行分解的计算开销很大
-
退而求其次:类似于speculative decoding的方法
- 先用更小的context length执行若干次推理
- 再用full context进行一次验证
- 为什么模型天然可以执行validation?因为输入$l$个token时,模型的输出是$l \times \text{n_vocab}$,其中第$(i, j)$个元素表示第$i$个token的下一个token是$j$的概率
- 因此只需要用某个token和上一个输出对比即可,假如相应的概率很小,说明两次推理结果发生冲突,采用validation的结果,并从抛弃这个token之后的结果,重新推理
- 可以在异构设备上进行,比方说CPU进行inference,GPU进行validation,充分利用GPU浮点性能强的优点
是否可以用StreamingLLM实现infinite context?https://arxiv.org/abs/2309.17453
什么是speculative sampling:
[2302.01318] Accelerating Large Language Model Decoding with Speculative Sampling (arxiv.org) (deepmind)
一个较快但计算能力较弱的draft model生成n个token (decoding),再交给target model进行一次验证(validation);假如验证通过就可以一次获得多个token
- pros:减少读取target model的次数,减少IO overhead
- cons:增加FLOPs
为什么在memory-constrained device上使用speculative是非常有效的?
- 将体积较小的draft model放在main memory
- 将体积较大的target model放在storage
- 只有由于validation的次数小于decoding,因此offload/prefetch的次数会下降
- decoding和validation可以并行,以掩盖IO的延迟
- validation也可以进行offload/prefetch
What is speculative sampling:
Speculative sampling is a process where a faster but less powerful draft model generates n tokens (decoding), which are then validated by the target model; if the validation is successful, multiple tokens can be obtained at once.
- Pros: Reduces the number of times the target model needs to be accessed, decreasing I/O overhead.
- Cons: Increases the number of floating-point operations (FLOPs).
Why is speculative sampling very effective on memory-constrained devices?
- The smaller draft model is kept in main memory.
- The larger target model is in storage
- The number of validations is less than the number of decodings, thus decreasing the number of offload/prefetch operations.
- Decoding and validation can occur in parallel to mask I/O latency.
- Validation can also be offloaded/prefetched.
Speculative decoding on memory-constrained device
fitting llama-2-13B (7.7GB) draft (3.0GB) into 3.5GB physical memory using speculative sampling in llama.cpp:

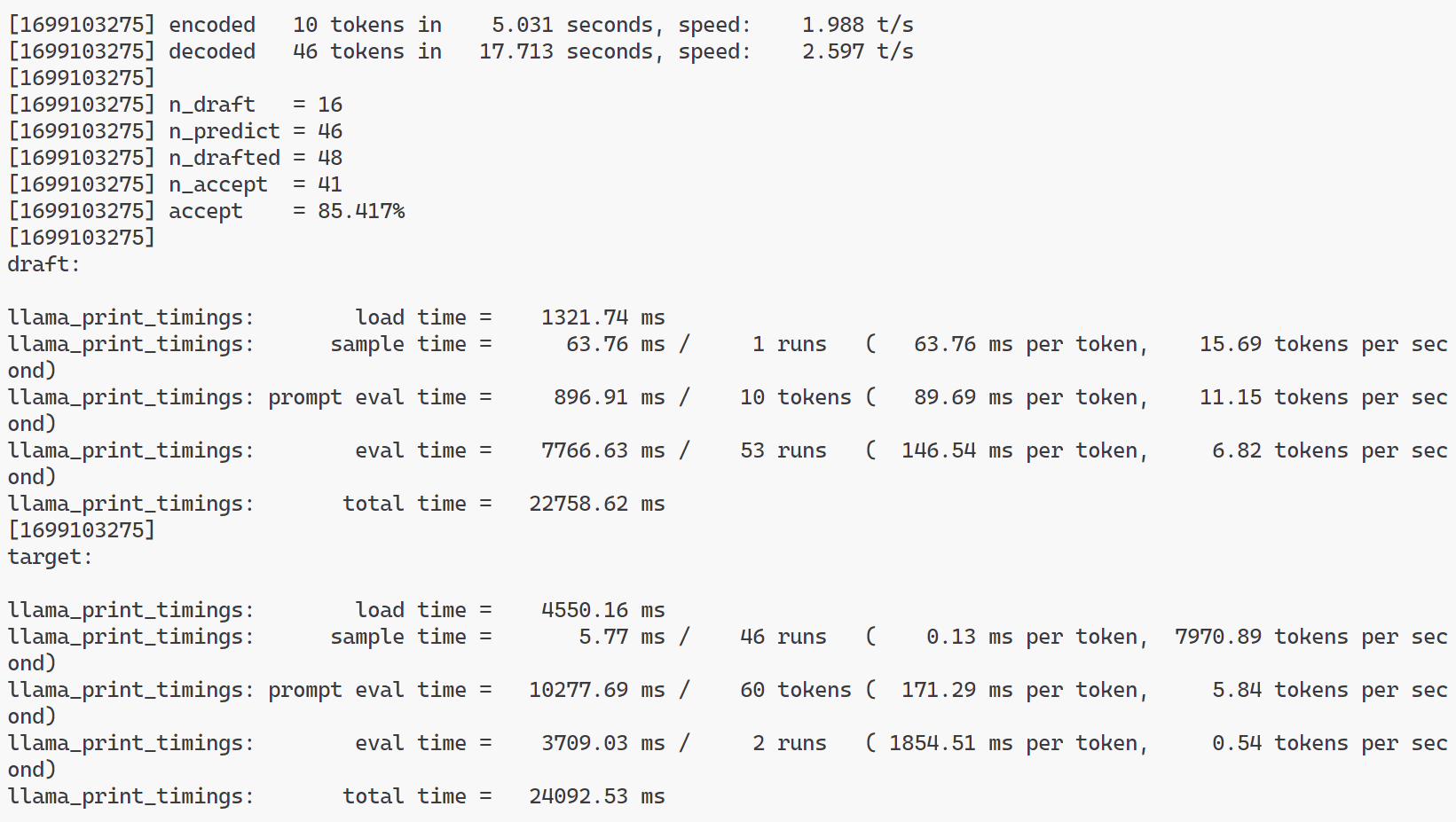
Speed limit for offloading:
- UFS 3.2 bandwidth: < 4GBps
- 每生成一个token就要使用所有weight一次,并且生成下一个token依赖于上一个的结果
可以探索的方向:
- offload/prefetch for target model
- 两个模型同时运行的资源分配调度
- validation调用的时机
- draft model选择;alignment with target model