vDNN
Abstract
提出了运行时内存管理器来虚拟化DNN内存使用,使GPU和CPU内存都可以同时用于训练更大的DNN。
批大小为256需要28GB内存的VGG-16能在内存12GB的Titan X上使用,且性能损失仅为18%。
Introduction
- 首次对基于GPU的DNN训练进行了详细定量的分析
- 从架构的角度对dnn的内存访问特性及其对GPU内存系统的影响进行了深入的研究
- 确定ML框架内存管理策略的限制——要求DNN全网络内存与GPU物理容量一致。10个现有框架中6个内存分配超出GPU内存的训练失败。
- 提出实现和评估了vDNN,跨CPU和GPU内存虚拟化神经网络的内存使用。将上述6个的平均GPU内存使用量降低了73-98%, 增加了1-18%的开销
Background and Motivation
概述现代DNN,ML框架的内存管理策略以及主要限制因素。
DNN Architecture
本文主要关注AlexNet、OverFeat、GoogLeNet和VGG。
DNN为多种层的结合(卷积层CONV、激活层ACTV、池化层POOL、全连接层FC)。
用于计算机视觉的DNN可以分为:
- 特征提取层,一般采用CONV/ACTV/POOL设计
- 分类层,一般用FC
DNN Training vs Inference
前向传播
前向传播过程中,只有前一层完成计算并输出时后一层才能开始计算,层间具有数据依赖关系。因此每一层所需最小内存由该层输入输出和数学公式决定。
反向传播
损失函数用于计算误差大小。
求第N层的输入输出梯度图和特征图都需要内存
输入通常是使用数百张图像进行批处理,增加内存分配大小,但是有助于模型收敛到最优解。
Motivation:Scalable and Memory-Efficient DNN Design
当使用现有的ML框架训练DNN时,跨网络所有层所需的内存必须符合GPU物理内存容量。这种gpu端、网络范围内的内存分配策略的关键原因是获得性能优势。基于页面迁移的虚拟化解决方案,都必须通过PCIe传输页面,这涉及到几个延迟密集型的过程,比如系统调用的CPU中断、页表更新、TLB更新/shootdown,以及实际的页传输。依赖页面迁移会导致巨大的性能损失(80-200MB/s——12.8GB/s)。
TLB shootdown:例如一个进程多个thread共享一个页表,每个CPU的TLB加载相同的页表,一个线程修改页表后需要使用IPI(inter-processor interrupt)告知其他CPU在TLB中禁用PTE(page table entry)
不管神经网络的深度如何,网络本身的训练仍然是分层进行的。因此,基准网络范围内的内存分配策略是非常浪费的,而且不可扩展,因为它没有考虑到分层DNN训练。
采用细粒度的、分层的内存管理策略可以节省大量内存。
Virtualized DNN
vDNN主要优化特征提取层的内存使用,大部分内存使用集中在这些层上。AlexNet81%, VGG-16(256)96%,同样也能用于权重和分类层只是收益较低。
Design Principle
采用基于滑动窗口的分层内存管理策略。运行时内存管理器保守地从其内存池中分配内存,用于GPU当前正在处理的层的即时使用。当前层不需要的中间数据结构用于内存释放,以减少内存使用。
前向传播
第n层的特征图前向传播完成计算后直到反向传播回来才回被重用。重用距离为ms到s的数量级。深度神经网络分配大量特征图的内存,实际上并没有被立即使用
vDNN有条件的将中间的特征图offload掉,通过PCIe、NVLINK等传给CPU的内存。卸载操作完成后,vDNN将卸载的特征图从内存池中释放出来,以减少GPU内存的使用。需要注意非线性计算图的依赖关系。
反向传播
如果一个层已经将X转移到主机内存中,vDNN应该保证在梯度更新开始之前将转移的数据复制回GPU内存中。vDNN会对层(n)的卸载特征映射进行预取操作,该操作与层(m)的反向计算重叠,并使n<m,这样在实际使用之前就进行了预取。隐藏预取延迟。
Core Operations and its Design
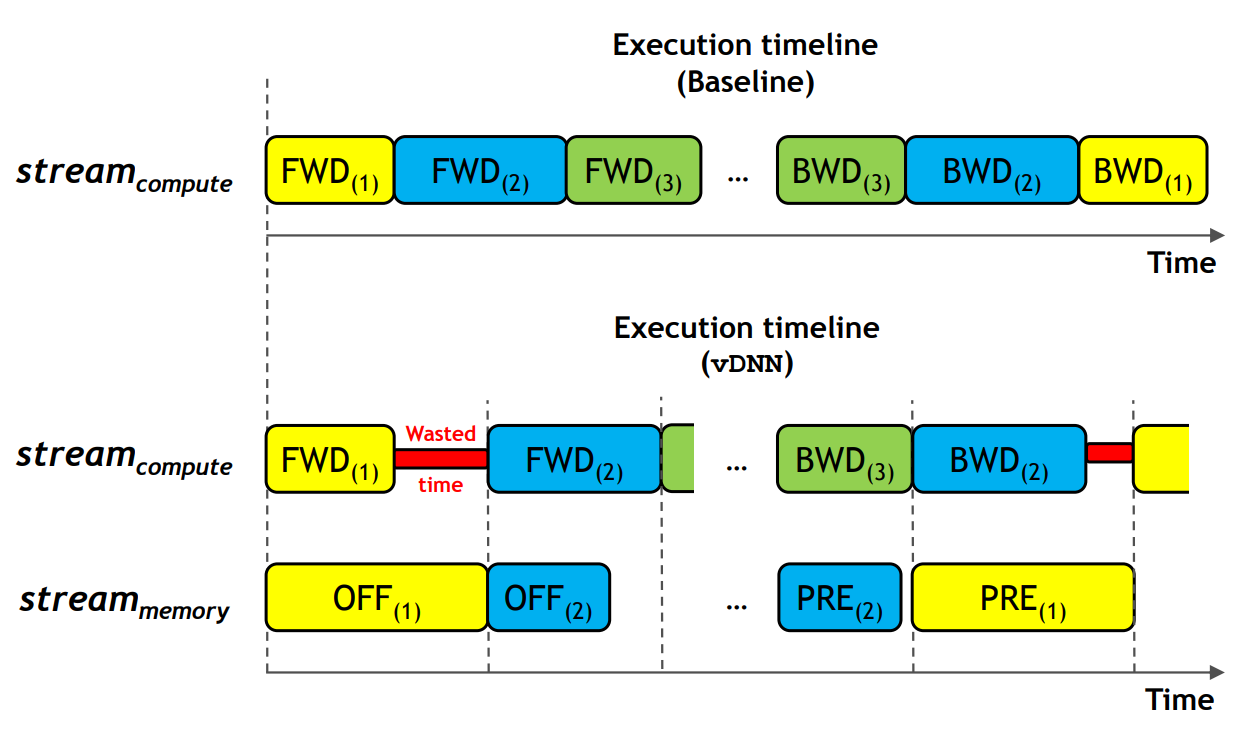
vDNN在cuDNN之上,每层都跟踪输入输出特征图的跨层数据依赖关系,便于正确调度vDNN offload和release。vDNN使用两个独立CUDA流,使正常DNN计算与vDNN内存分配移动和释放重叠。stream~compute~ 是CUDA流,连接到cuDNN处理,并对前向和反向传播排序。stream~memory~ 管理vDNN的分配释放、卸载、预取。
内存分配与释放
CUDA库只支持同步的内存分配与释放,则任何cudaMalloc和cudaFree都必须有额外的同步。本文使用了NVIDIA的开源异步内存分配释放NVIDIA, “https://github.com/NVIDIA/cnmem,” 2016。
程序启动时vDNN内存管理器被分配一个与GPU内存大小相同的内存池。分配和释放时,底层内存管理器在内存池中操作,不调用cuda函数。
内存卸载
当要卸载一个层的时候,vDNN先使用cudaMallocHost分配主机端的固定内存区域,stream~memory~启动使用cudaMemcpyAsync()通过PCIe将该层的X进行非阻塞内存传输到固定内存,并将其与cuDNN同一层的正向计算重叠。如果stream~memory~已经卸载特征图,每层前向传播结束时同步stream~compute~和stream~memory~。(确保下一层计算开始前已卸载数据安全的从内存池中释放。) CONV和POOL的X都是只读数据,将卸载与前向传播重合不会产生问题。ACTV已经被重构为就地算法,不需要卸载内存。
内存预取
使用cudaMemcpyAsync将卸载的X预取回GPU内存,将数据传输和反向传播计算重合。stream~memory~预取操作顺序与正向传播相反。反向传播的时候,预取当前层前面层的卸载数据。
如果预取层与重用层距离不能太远。
// currLayerId: 当前层ID
// layers[n]->offloaded: 卸载特征图时为true
// layers[n]->prefetched: 所有层初始为false
int Network::findPrefetchLayer(int currLayerId)
{
// 搜索前面的所有层
for(int id=(currLayerId-1); id>=0; id--) {
// 找到离当前层最近的需要预取的层
if( (layers[id]->offloaded==true)&&(layers[id]->prefetched==false) )
{
// 设置对应flag
layers[id]->prefetched = true;
return id;
}
// 直到窗口末尾都没找到符合条件的预取层
else if(layers[id]->layerType==CONV)
{
return -1;
}
}
}
找到ID后,stream~compute~和stream~memory~进行同步。
vDNN Memory Transfer Policy
确定最佳卸载特征图需要考虑:
- GPU内存容量
- 使用的卷积算法和整体分层内存使用情况
- 整个网络的性能
对每层都尽量使内存使用率最低,与基准相比性能会有损失。采用启发式内存传输策略。
static vDNN
特征提取层主要为CONV和ACTV,POOL用于减少特征图大小,大量计算时间花在CONV上。
A:让vDNN内存管理器卸载所有层的所有X(输入)——vDNN~all~。
B:只卸载CONV的X——vDNN~conv~,因为CONV有更长的计算延迟,可以隐藏卸载和预取的延迟。
使用内存最优和性能最优的卷积算法来评估这两个静态策略的内存使用和性能。
dynamic vDNN
静态vDNN简单且易于实现,但它没有考虑到决定DNN可训练性和性能的系统架构组件(例如,最大计算FLOPs和内存带宽、内存大小、有效PCIe带宽等)。
使用了一个动态vDNN策略,自动确定卸载层和运行时使用的卷积算法,以平衡DNN的可训练性和性能。首先利用cuDNN的运行时API(对给定层所有可用卷积算法进行测试,评估每种算法的性能和内存使用情况),作为初始配置阶段,以确定为每个CONV层部署的最佳算法,以获得最佳性能。这种分析的开销大约是几十秒,相对于DNN培训所需的几天到几周,这是微不足道的。动态vDNN通过一些额外的分析通道来增加这个分析阶段,以选择要卸载的最佳层和每层最佳算法。基准分析完成并为所有CONV推出最快算法后,vDNN有以下方案:
- 使用内存最优、不导致WS(workspace)的算法对静态vDNN~all~所有CONV测试,决定DNN是否能被训练。
- 如果vDNN~all~通过,则启动另一个阶段。所有CONV使用最快的算法但不卸载。如果通过,则当前配置用于其他训练部分。如果内存不够,则先使vDNN~conv~可卸载后测试,再对vDNN~all~启用卸载。成功则使用成功的配置。
- 如果都不能成功,则使用一种贪心算法,试图减少一层的内存使用,在可训练性和性能方面寻求全局最优。遍历每一层的时候,首先计算最快的算法是否导致内存不足,如果是,则这层的算法降级为性能较差但内存消耗少的,直到达到内存最佳隐式GEMM。首先尝试VDNN~conv~,每个CONV层最初使用自己的性能最优算法。如果vDNN~conv~失败,则使用内存效率更高的vDNN~all~启动另一个训练通道。如果vDNN~all~在这个贪心算法上也失败了,则使用方案1。
Methodology
vDNN Memory Manager
主机端内存管理器与cuDNN4.0交互作为GPU后端。每一层都用两个cuda流,即stream~compute~和stream~memory~。分类层保持不变,使用Torch中相同的cuBLAS。
选择Torch的内存管理策略作为基准与vDNN比较。
GPU Node Topology
在Nvidia的Titan X上进行实验,它提供了Maxwell gpu家族中最高的数学吞吐量(单精度吞吐量为7 TFLOPS)、内存带宽(最大336 GB/s)和内存容量(12 GB)。GPU通过PCIe交换机(gen3)与Intel i75930K(含64GB DDR4内存)进行通信,最大传输带宽为16 GB/s。
Results
GPU Memory Usage
最大内存使用量和平均内存使用量。
平均内存使用量越小,vDNN就越有可能通过以下方式提高性能:
- 使用需要更大工作空间的高效卷积算法
- 减少卸载层的总数,并防止卸载导致的潜在性能下降
