Band阅读笔记
Band: Coordinated Multi-DNN Inference on Heterogeneous Mobile Processors
MobiSys 22 (CCF B)
cited: 19
一句话总结
提出了BAND,用于在异构处理器上协调多DNN工作负载。
问题背景
目前最先进的移动深度学习框架,包括TensorFlow Lite [8]、MNN [29]、Mace [7]和NCNN [4],并不完全适合为移动应用提供服务,因为它们是为尽可能快速地执行单个DNN而开发和优化的。尽管现代移动设备配备了多个用于DNN计算的处理器,如Edge TPU [5]、Hexagon DSP [11]和Google Pixel 4上的Adreno GPU,但框架会指定一个快速处理器,并优先使用该处理器来运行DNN。在处理多个推理请求时,它们失去了利用所有处理器的机会。虽然在技术上可以在一个处理器上运行多个DNN,但移动处理器资源有限,无法独立为多DNN工作负载提供合理的性能。
挑战
-
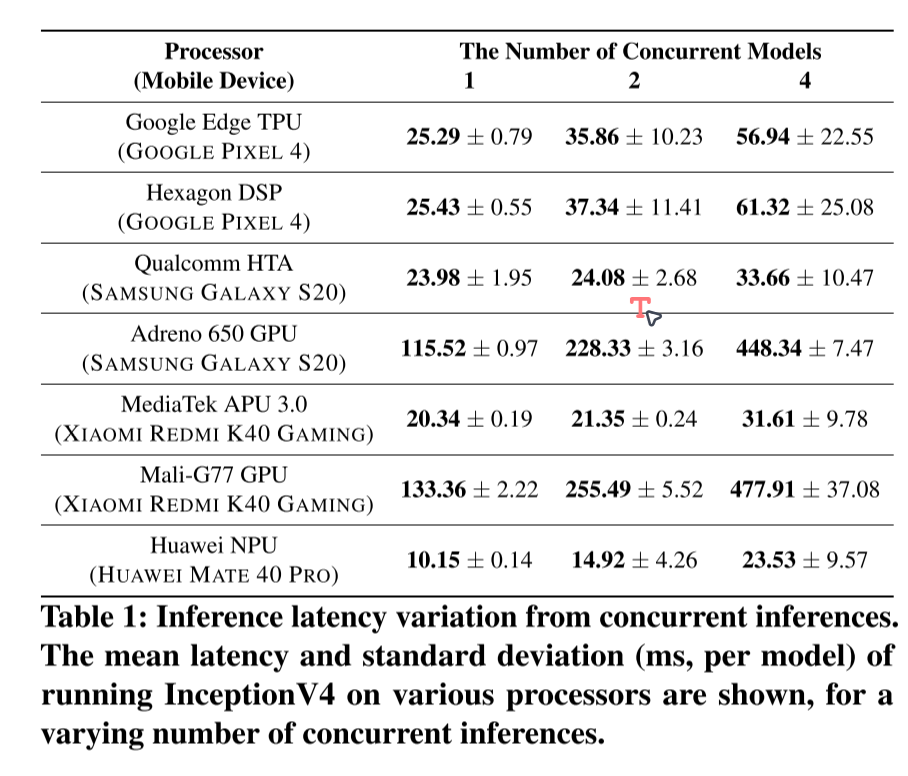
处理器争用:对于大多数处理器,随着模型数量的增加,延迟迅速上升
-
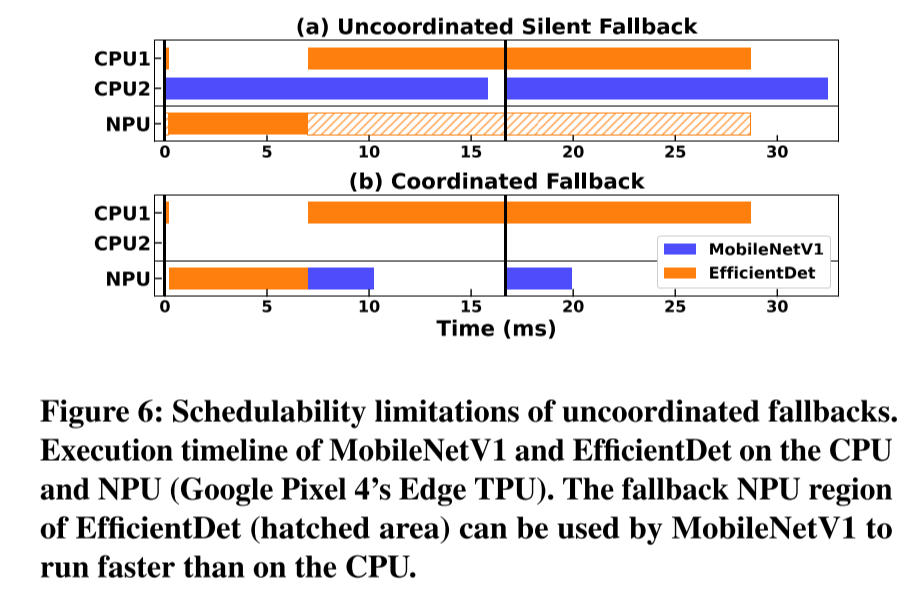
Fallback:现有框架遇到不支持的算子时会自动fallback到CPU,这带来两个问题:
-
不进行协调的回退会阻止其他操作符访问空闲的处理器
-
其他非CPU加速器未被考虑作为fallback的选项
-
-
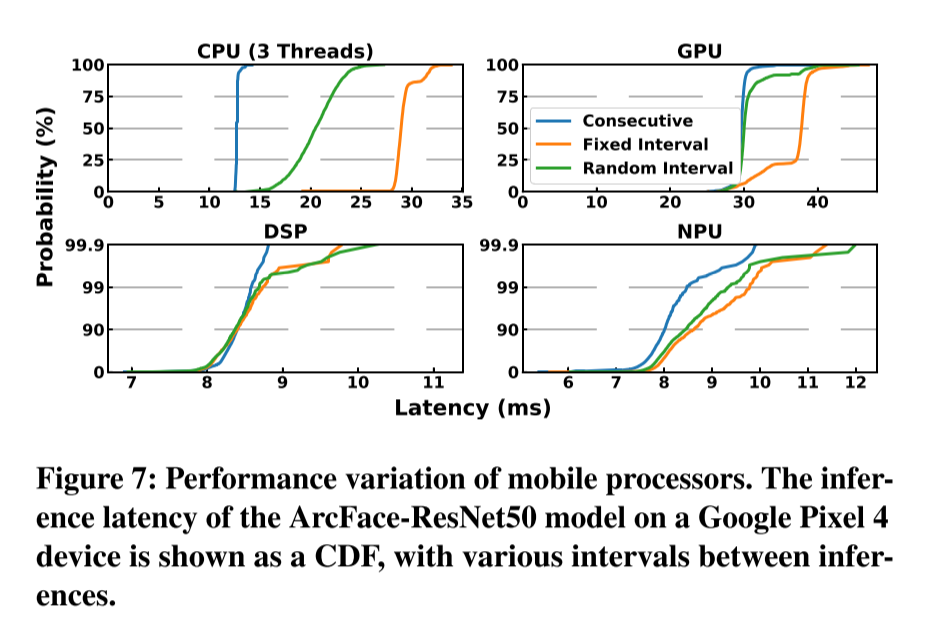
性能建模的不确定性:
-
如果我们在每次推理之间让处理器空闲较长时间,处理器频率会下降,再次推理时延迟相对较大;
-
DSP和NPU是与主芯片组松散耦合的独立硬件加速器,因此,对DSP或NPU的任何计算都需要通过多层接口进行通信,这会导致性能波动
-
方法
客户端应用程序首先通过RegisterModel通知BAND它们将使用的DNN模型。在接收到模型后,模型分析器检查模型并生成模型的子图;接下来,客户端通过RunModel发出推理请求。请求以作业的形式进入由调度器管理的队列。作业是一个内部数据结构,包括请求的模型和输入数据,以及请求元数据,如SLO值(预期处理延迟)和请求应用ID。根据分析器提供的子图信息,调度器从其队列中出队一个作业,并根据可插拔的调度策略为作业选择一个适当的子图,并在适当的处理器上安排子图。子图运行完成后,如果子图覆盖了整个模型,则将推理结果返回给客户端。否则,作业将重新进入队列,并相应地标记其执行进度。
值得注意的是,BAND为每个可用的处理器生成专用的工作线程。一个工作线程一次最多在其处理器上运行一个子图。每个处理器的工作线程数量由可配置的系统参数调整,以避免处理器竞争问题。
子图生成
模型分析器不是直接从操作符创建子图,而是通过两个步骤创建子图。首先,模型分析器从操作符生成单元列表(图10a)。
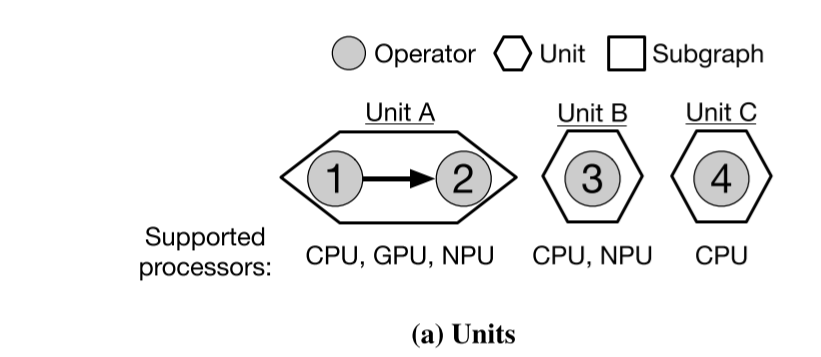
单元是一组相邻的操作符,它们都由完全相同的处理器集合支持。每个操作符只属于一个单元,即没有两个单元具有共同的操作符。此外,单元尽可能大。例如,操作符1和2形成一个由CPU、GPU和NPU支持的单元。操作符3被制作成一个单操作符单元,因为它的相邻操作符(2和4)由不同的处理器集支持。
子图生成过程从为每个单元创建一个单单元子图开始。之后,如果相邻单元至少有一个共同支持的处理器,它们可以合并成更大的子图。例如,子图{1,2,3}是从{1,2}和{3}生成的。{1,2,3}的受支持处理器集合是{1,2}和{3}的处理器集合的交集。请注意,在合并过程中,原始的小子图不会被丢弃。
子图调度
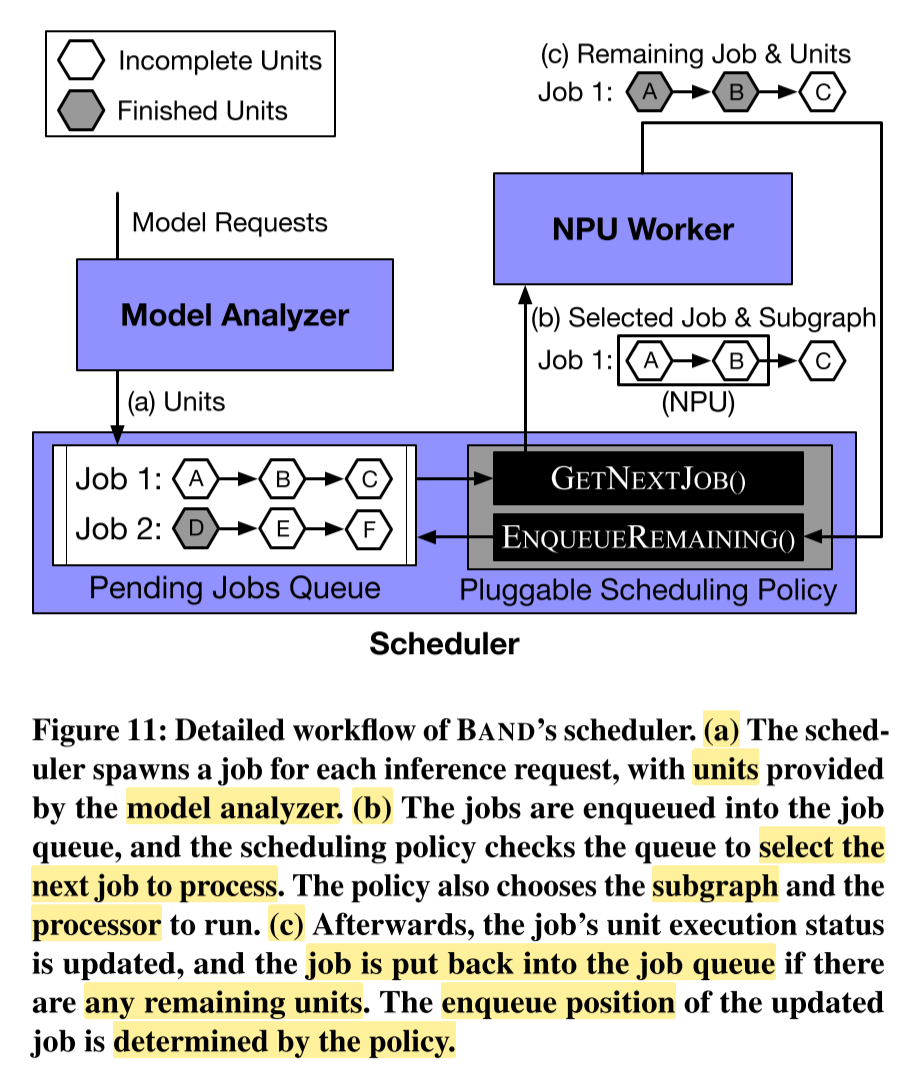
- 调度器为每个推理请求生成一个作业,模型分析器提供单元。
- 作业被加入作业队列,调度策略检查队列以选择下一个要处理的作业、子图和处理器。
- 之后,更新作业的单元执行状态,如果还有剩余单元,则将作业重新放回作业队列。更新后的作业的入队位置由策略确定。
其中最重要的过程是选择作业和子图。
每个调度策略都有自己的逻辑来选择作业及其子图。图12说明了BAND的默认LST策略如何为给定的作业集选择作业和子图。策略通过比较作业的SLO与其预期延迟来检查每个作业的松弛时间。
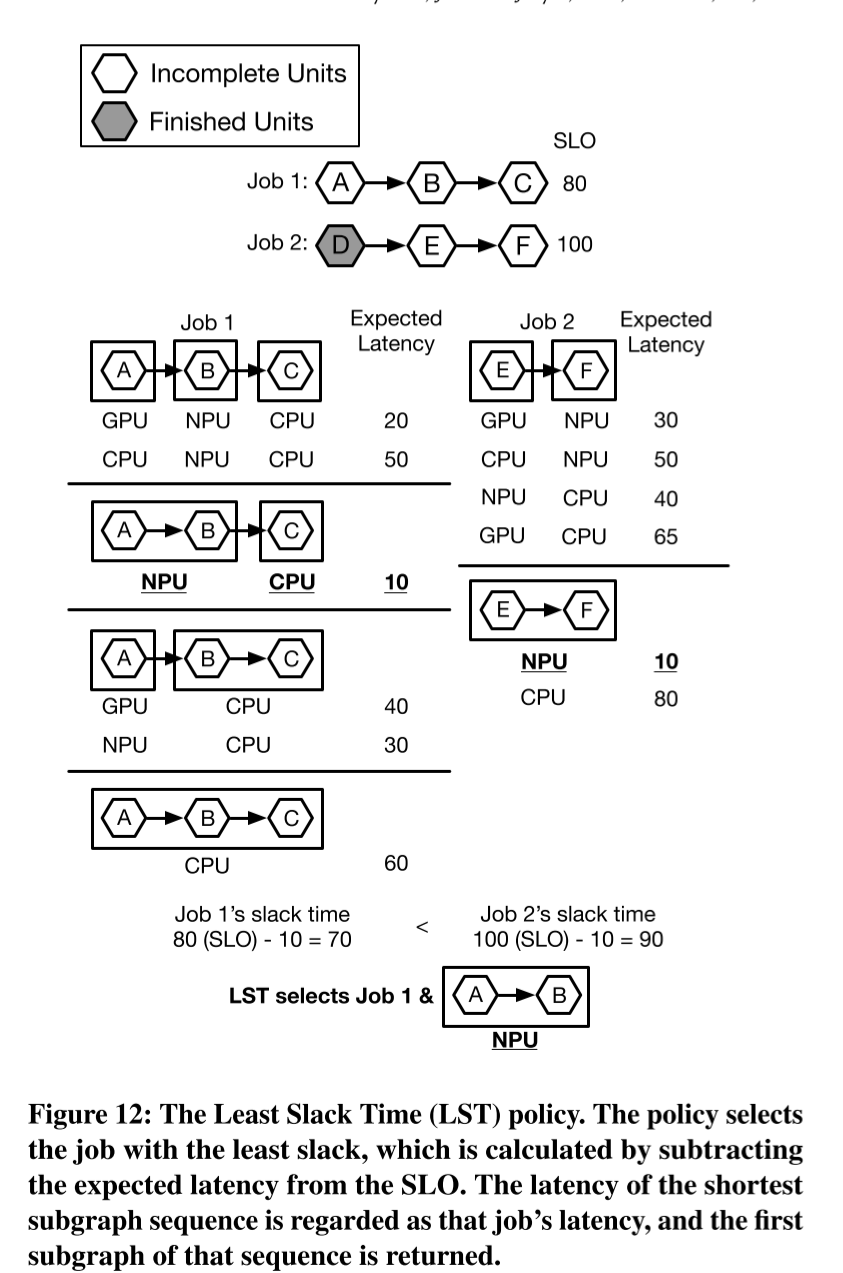
由于作业的预期延迟取决于为作业运行哪些子图,策略考虑所有有效的子图序列,并选择延迟最短的序列。此外,单个子图序列可能具有多个预期延迟,因为至少有一个子图可以在多个处理器上运行,例如序列{A}-{B,C}。在这种情况下,仅考虑导致最低预期延迟的处理器({A}(NPU)- {B,C}(CPU))。最后,选择松弛时间最短的作业和该作业的子图序列的第一个子图。作业1的松弛时间为70(=80-10),因为它的SLO为80,子图序列{A,B}(NPU)- {C}(CPU)的预期延迟为10。作业2的松弛时间为90(=100-10),因为它的SLO为100,子图序列{E,F}(NPU)的预期延迟为10。因此,选择作业1和子图{A,B}(NPU)。
请注意,子图序列的预期延迟并不等于每个单独子图的分析执行时间之和。通常,在调度时,其他作业的子图已经在处理器上执行,因此预期延迟通常大于执行时间之和。因此,调度器必须在每次调用GETNEXTJOB()时动态计算预期延迟。我们发现,对于所有可能的子图序列进行简单的穷举搜索在运行时会产生显着的调度开销-对于具有p个兼容处理器的n个子图,穷举搜索的复杂度为$O(p^n)$(对于单个作业)。相反,LST策略运行基于动态规划的算法,将复杂度降低到$O(pn^2)$
接下来的问题是如何估算子图在某个处理器上的执行时间。
当注册新模型时,BAND依次在每个可用处理器上运行模型的最大子图并记录延迟。在获取每个可用处理器的最大子图的执行时间值后,BAND测量每个子图的浮点操作数(FLOPs)以及输入和输出张量的大小。假设子图的执行时间大致与$\text{FLOPs} + \beta \times \text {张量大小}$成比例。β是一个常数,反映了内存复制和计算之间的比例;在我们的实验中,对于加速器,我们使用了1,000的值,对于CPU,我们使用了10的值,因为加速器执行运算通常比CPU快。最后,我们使用简单的线性平滑函数在运行时调整子图的延迟配置文件:$time_{profiled} \leftarrow \alpha \ time_{new} + (1 - \alpha) time_{profiled}$。α是0到1之间的可配置系统参数。我们发现,α值为0.1时性能良好。
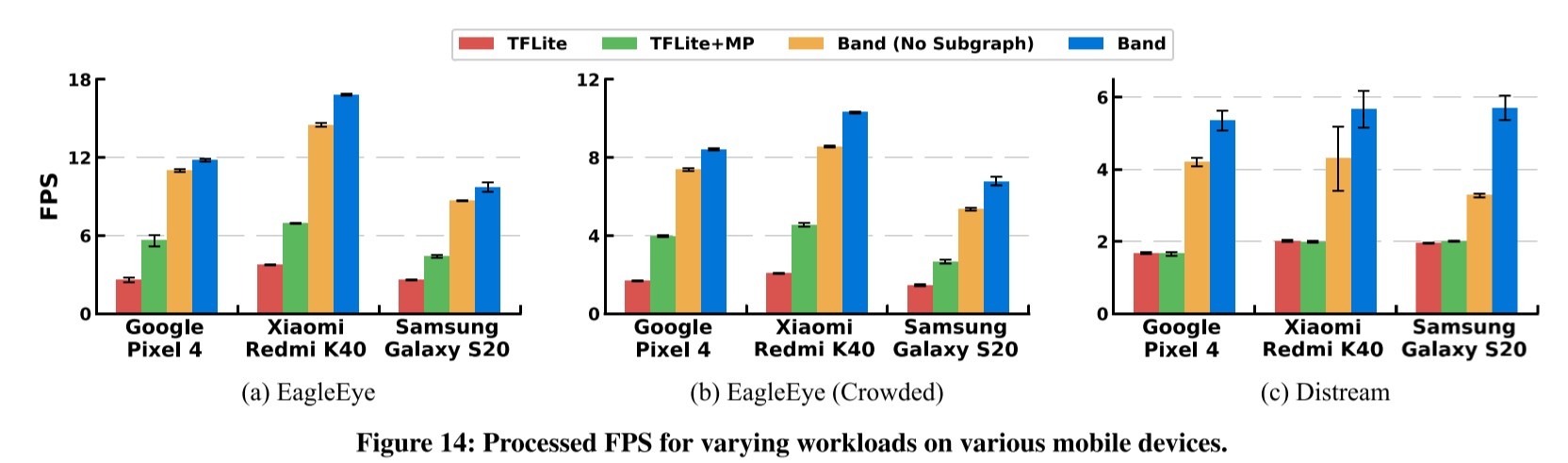
实验
在TensorFlow Lite 2.3.0基础上实现